【JMM】内存模型之重排序
定义
重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段。
例如,如果一个线程写入值到字段 a,然后写入值到字段 b,而且 b 的值不依赖于 a 的值,那么,处理器就能够自由的调整它们的执行顺序,而且缓冲区能够在 a 之前刷新 b 的值到主内存。
数据依赖
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。
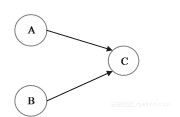
如图所示,A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。
as-if-serial语义
as-if-serial语义的意思是,所有的操作均可以为了优化而被重排序,但是你必须要保证重排序后执行的结果不能被改变,编译器、runtime、处理器都必须遵守as-if-serial语义。注意as-if-serial只保证单线程环境,多线程环境下无效。
as-if-serial语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
重排序类型
- 编译器优化的重排序
编译器在不改变单线程程序语义的前提下,可以重新安排语义。 - 指令级并行的重排序
代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。 - 内存系统的重排序
由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序。

禁止重排序
- 只要volatile变量与普通变量之间的重排序可能会破坏volatile的内存语义,这种重排序就会被编译器排序规则和处理器内存屏障插入策略禁止。
- JMM的处理器重排序规则会要求Java编译器在生成指令序列时,插入特定类型的内存屏障(Memory Barriers,Intel称之为Memory Fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序。
- 在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。(防止拿到对象时,final域还未赋值);初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序。
重排序对多线程的影响
重排序不会影响单线程环境的执行结果,但是会破坏多线程的执行语义。
参考
《Java并发编程的艺术》一一3.2 重排序
啃碎并发(11):内存模型之重排序
【细谈Java并发】内存模型之重排序
【死磕Java并发】—–Java内存模型之重排序
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 ClawHub的技术分享!