深入了解Redis【十八】一致性Hash算法在Jedis客户端中的应用
引言
一致性hash算法用于在集群环境中,使得节点的增加或者减少对于整个集群中的数据来说影响返回达到最小。
一致性hash算法
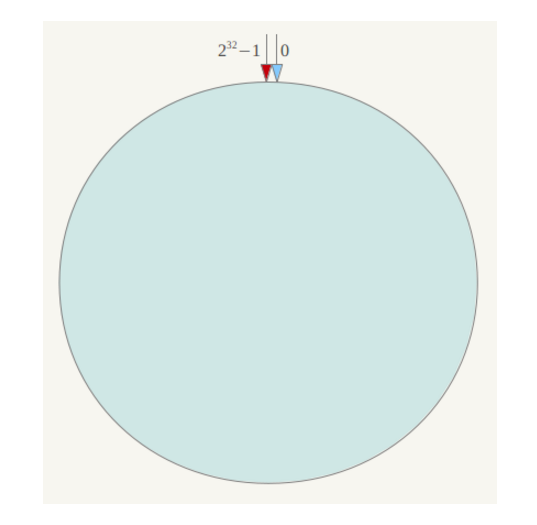
一致性hash算法将整个hash值空间组成一个虚拟的环,整个空间按照顺时针方向组织。
算法简答描述:
盗图:一致性哈希算法原理
假设hash值空间为32位无符号整型,整个hash空间如图:
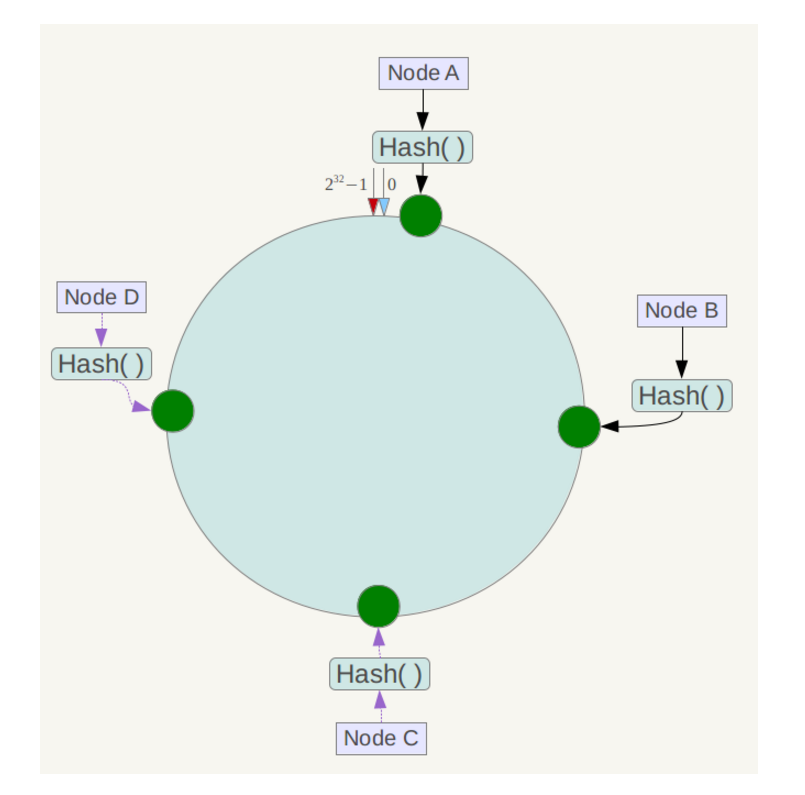
服务器节点的位置确定
将服务器节点通过名称进行hash,这样每台服务器节点都能座落到hash环上(假设4个节点),如图:
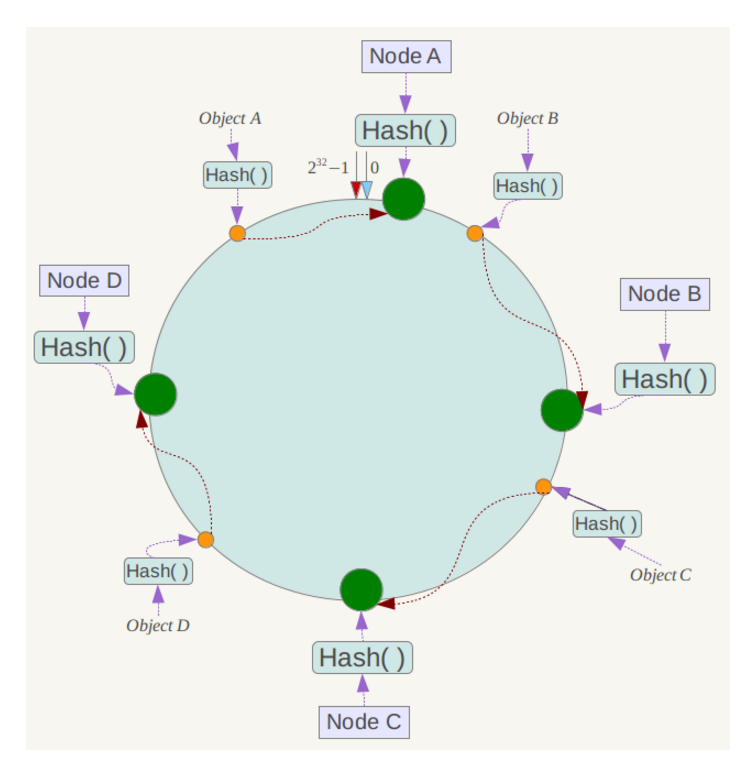
数据对象的位置确定
如果有数据过来,使用与服务器节点相同的hash算法,将key定位到hash环上,从这个位置沿着hash环顺时针查找,第一个遇到的服务器节点就是其归属服务器。
假设有4个数据,经过计算后,在环上的位置如下:
容错性
假设其中的一个节点宕机,则受影响的数据仅仅是次服务器到其逆时针查找遇到的第一台服务器之间的数据,其他不受影响,如图:
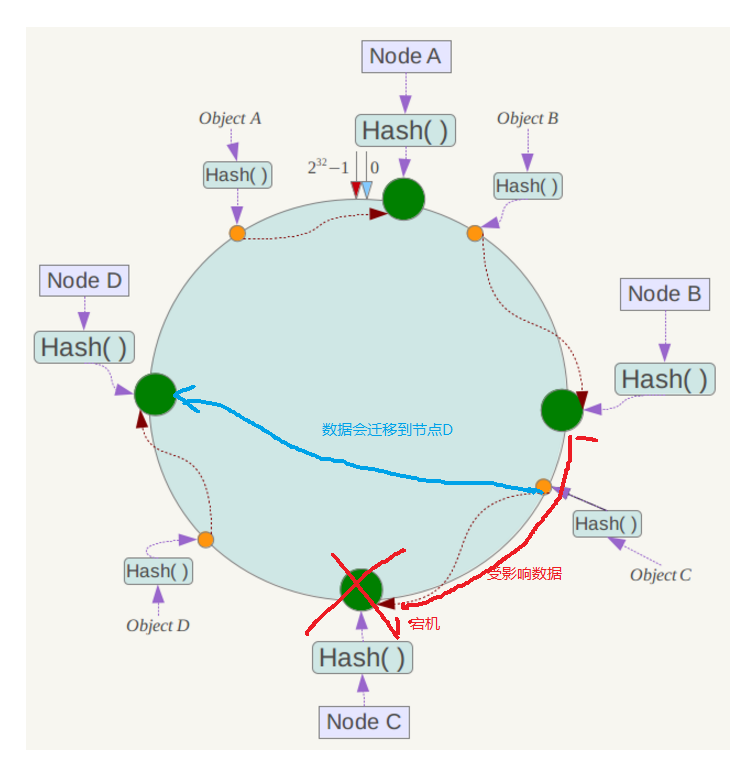
扩展性
假设增加一台服务器,则受影响的仅仅是新加入的服务器到其逆时针查找遇到的第一台服务器之间的数据,其他不受影响,如图:
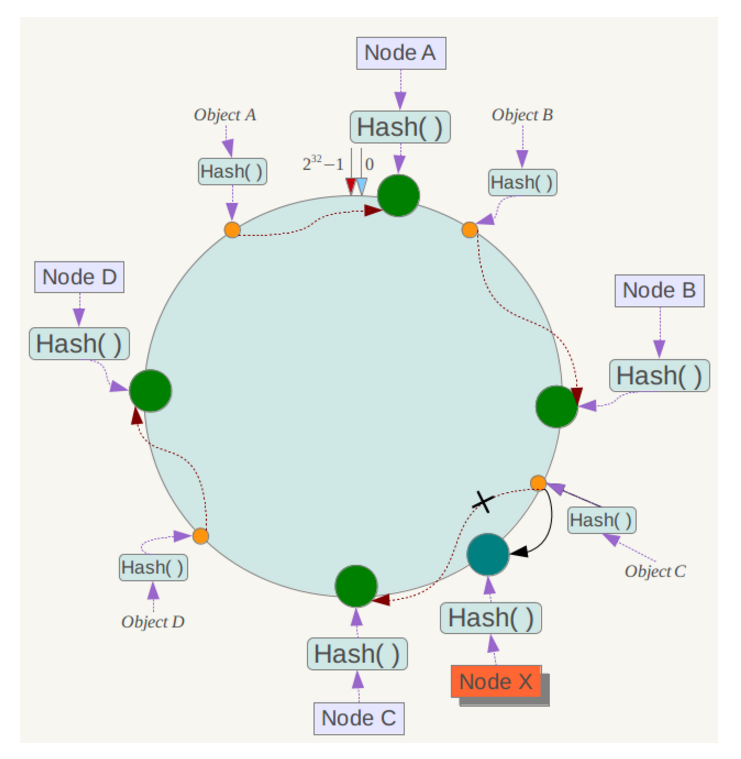
数据倾斜问题与虚拟节点
假设有两个服务器节点,其分布图如下:
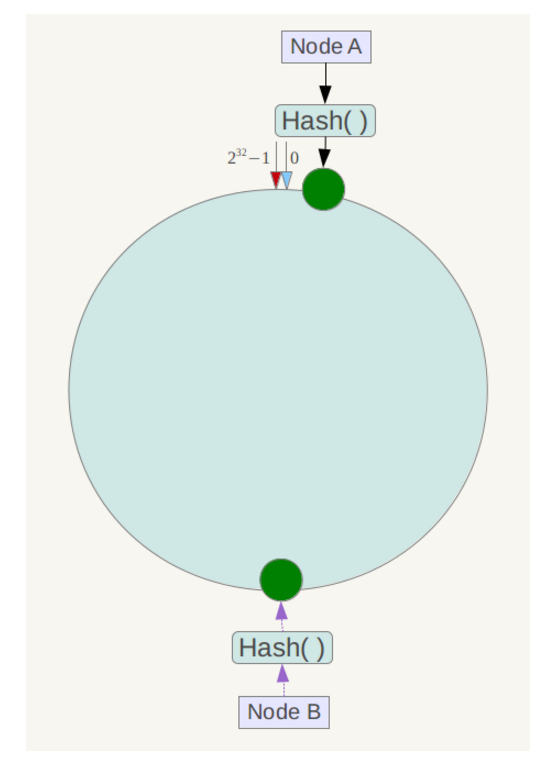
当数据分布不均匀时,容易数据倾斜,以至于一个节点压力过大,另一节点空闲造成资源浪费。
为了解决这个问题,引入了虚拟节点机制,对于一个节点,多次计算hash值(名称+变化权重值*总虚拟节点数,这里可以参考Jedis客户端的Sharded类)。
这样一台服务器对应了hash环中的多个虚拟节点,当数据坐落到虚拟节点的时候,查找对应的真实节点,这样就解决了数据倾斜问题。
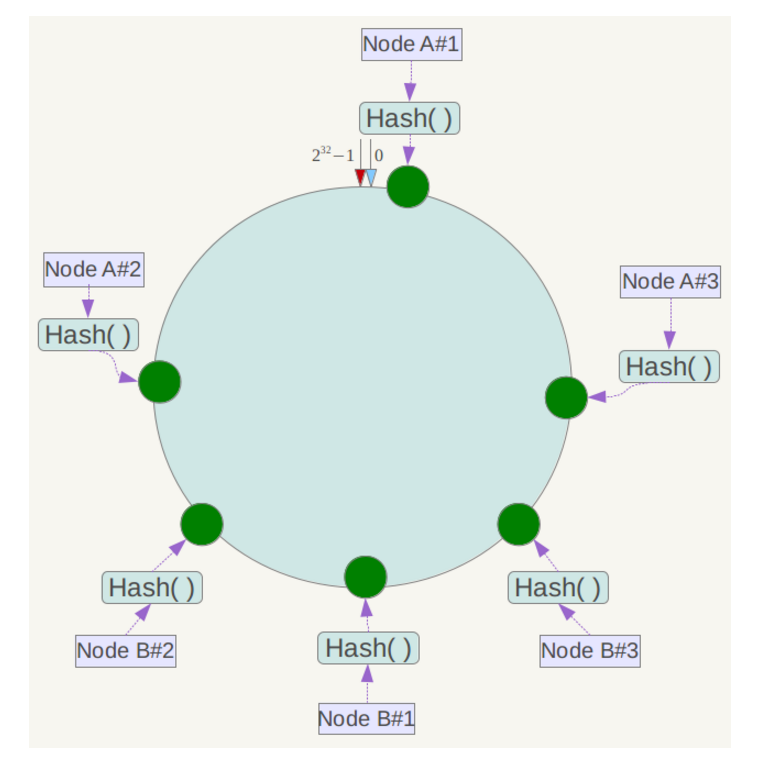
Jedis客户端中的一致性hash
我这里使用Jedis 2.9.0版本。
ShaededJedis一致性hash实现思路:
- 将所有服务器节点根据权重划分为160个虚拟节点
- 对于key和虚拟节点都使用相同的hash算法(默认MurmurHash)
- 所有虚拟节点使用TreeMap存储
- 所有真实物理节点采用LinkedHashMap存储
- 操作key时,通过hash算法得出hash值,从TreeMap中获取大于此键hash值的节点,取最邻近的节点存储,当此键hash值大于虚拟节点hash值最大值时,存入第一个虚拟节点。
数据定义源码:
redis.clients.util.Sharded
1 | public static final int DEFAULT_WEIGHT = 1; |
划分虚拟节点逻辑源码:
redis.clients.util.Sharded的initialize方法:
1 | private void initialize(List<S> shards) { |
操作数据源码
以set为例子:
redis.clients.jedis.ShardedJedis
1 | public String set(String key, String value) { |
通过getShard方法获取到Jedis客户端:
1 | public R getShard(String key) { |
这里的resources就是上面介绍的真实物理节点。
再来看getShardInfo方法:
1 | public S getShardInfo(String key) { |
这里的nodes是虚拟节点。
总结一下就是通过key获取虚拟节点,在通过虚拟节点获得物理节点的客户端,最后正常操作redis客户端。
参考
一致性哈希算法原理
Jedis之ShardedJedis一致性哈希分析