深入了解Mysql【六】一条SQL语句的执行过程
在开始本篇之前,先贴一张图: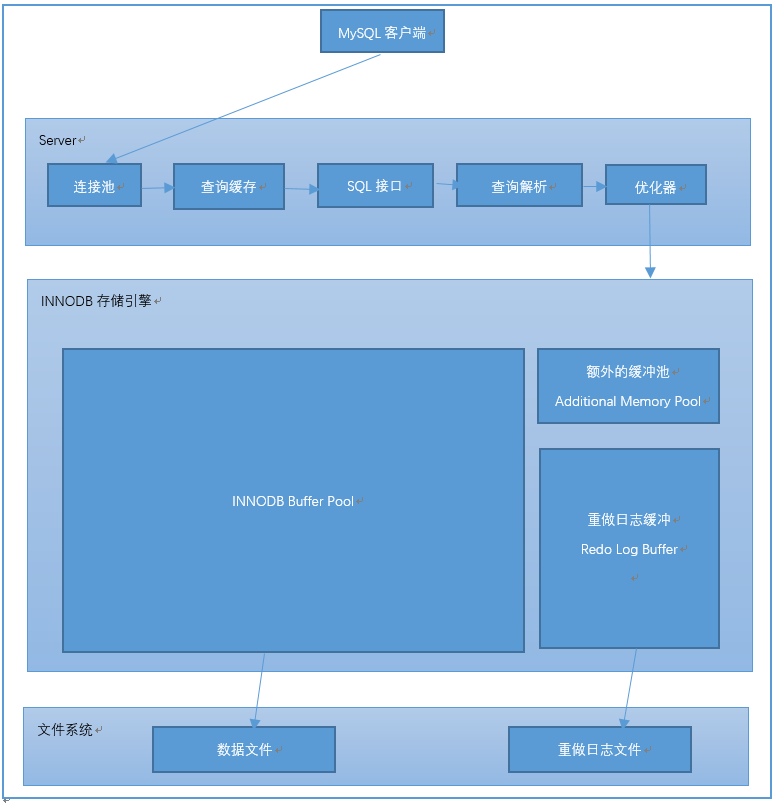
图中大概的标出了SQL执行过程的走向。
SQL语句的执行顺序
- 客户端通过TCP发送连接到MySQL服务器,服务器端的连接池会对请求进行鉴权验证以及资源分配。
- 如果开启了缓存,且是一条查询语句,则进入查询缓存模块,判断是否被缓存过,如果命中缓存,则直接返回结果,否则下一步。
- 进入SQL接口模块,进行简单的语法校验。
- 进入解析模块,进行语句解析。
- 将解析好的语句转给优化器,生成执行计划。
- 再进入InnoDB引擎,首先会判断该SQL涉及到的页是否在缓存中,如果不存在,则从磁盘读取相应的索引及数据页,加载到缓存。
- 如果是查询语句
使用一致性非锁定读,读取数据,并将查询结果返回到服务层。 - 如果是DML语句
读取到相关页,先试图给这个SQL涉及到的记录加锁。加锁成功后,先写Undo页,逻辑的记录这些修改前的状态。
然后修改相关记录,这些操作会同步物理的记录至redo log buffer。如果涉及非唯一辅助索引的更新,还需要使用insert buffer。
事务提交时,会启用内部分布式事务,先将SQL语句记录到binlog中,再根据系统设置,刷新redo log buffer到redo log,保证binlog与redo log的一致性。
提交后,事务会释放对这些记录所加的所,并且将这些修改的记录所在的页放入到InnoBD的flush list中,等待被page cleaner thread刷新到磁盘。
这个事务产生的undo page如果没有被其他事务引用(insert 的undo page不会被其他事务引用),就会被放入到history list中,等待被purge线程回收。
参考:
[小结]InnoDB体系结构及工作原理
MySQL中一条SQL语句的执行过程

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 ClawHub的技术分享!