深入了解Zookeeper【五】选举原理
1、概述
Leader选举是Zookeeper保证分布式数据一致性的关键,上一篇简单的了解了Paxos算法和ZAB机制,本篇来简单学习一下选举原理。
2、节点角色
Zookeeper集群中的服务器节点有3中角色:Leader、Follower、Observer。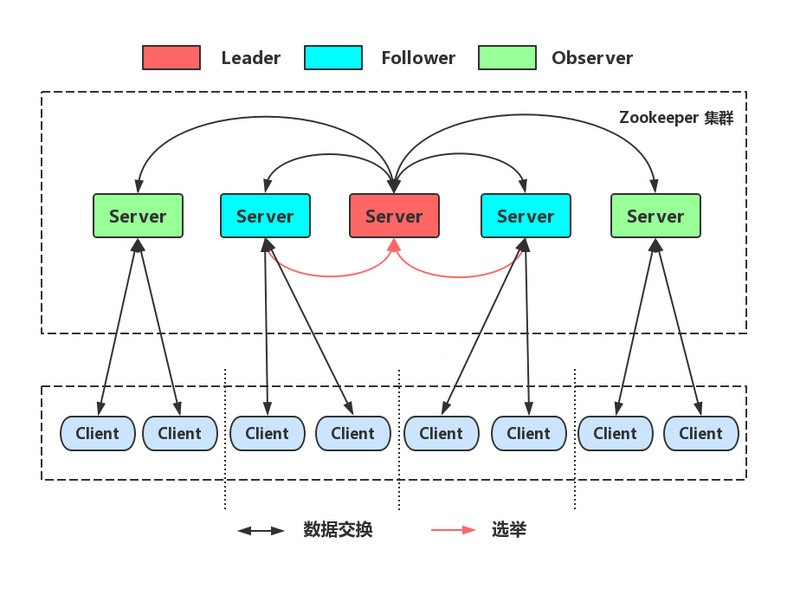
2.1、Leader
Leader是Zookeeper集群中的核心,主要负责集群内部各个节点的调度,还要负责事务处理的顺序性。
2.1、Follower
- Follower直接处理非事务请求,对于事务请求会交给Leader。
- 在Leader处理事务请求时,参与决策投票。
- 选举Leader时参与投票。
2.1、Observer
不参与投票,只为了增加Zookeeper集群的非事务处理能力。必须在配置文件中指定哪些节点是Observer。
3、选举时机
- 集群中服务启动时会发生选举。
- 在集群运行过程中,Leader崩溃时会发生选举。
4、节点状态转换
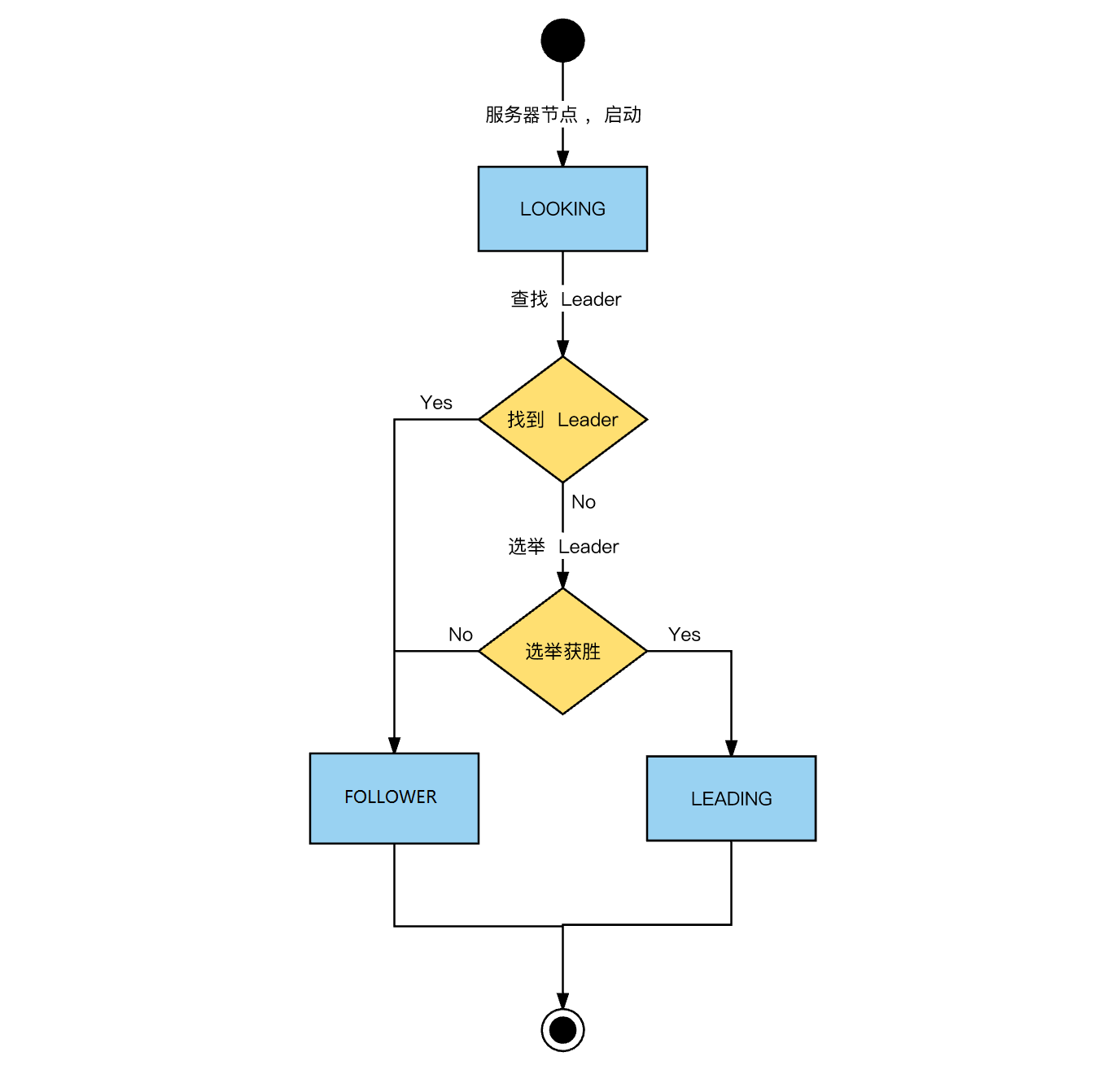
图中只涉及Leader与Follower。
5、投票的信息
| 属性 | 说明 |
|---|---|
| id | 被推举 Leader 的 sid |
| zxid | 被推举 Leader 的事务ID |
| electionEpoch | 投票的轮数,约束:同一轮投票,计数有效 |
| peerEpoch | 被推举 Leader 的 epoch |
| state | 当前服务器的状态 |
6、选举过程
- 各个节点广播自己的优先级标识(sid,zxid)
- 当前节点收到其他节点的广播消息后,跟自己的优先级标识做比对,自己优先级低,则变更当前节点的投票的优先级标识,并广播变更后的结果。
- 当任何一个节点收到的投票数超过集群半数以上,则升级为Leader,并广播结果。
以一个例子描述整个选举过程:
假设有5台服务器组成Zookeeper集群,sid由1到5,是新建集群,无数据,服务器依次启动。
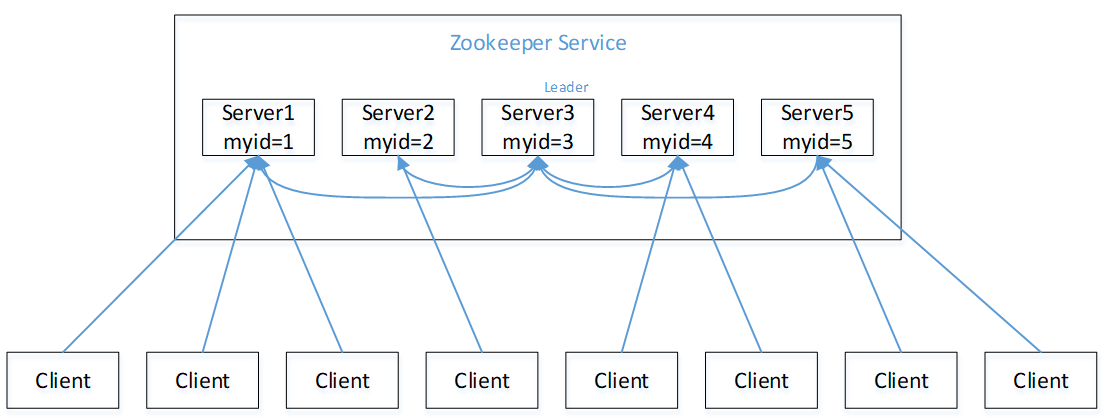
- 服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
- 服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的ID比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
- 服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
- 服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
- 服务器5启动,同4。
7、脑裂问题
- 假死
由于心跳超时(网络原因导致的)认为master死了,但其实master还存活着。 - 脑裂
由于假死会发起新的master选举,选举出一个新的master,但旧的master网络又通了,导致出现了两个master ,有的客户端连接到老的master 有的客户端链接到新的master。
Zookeeper采用半数投票机制解决脑裂问题,要么选举中唯一的Leader,要么选举失败。
参考

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 ClawHub的技术分享!