深入了解Netty【八】TCP拆包、粘包和解决方案
1、TCP协议传输过程
TCP协议是面向流的协议,是流式的,没有业务上的分段,只会根据当前套接字缓冲区的情况进行拆包或者粘包: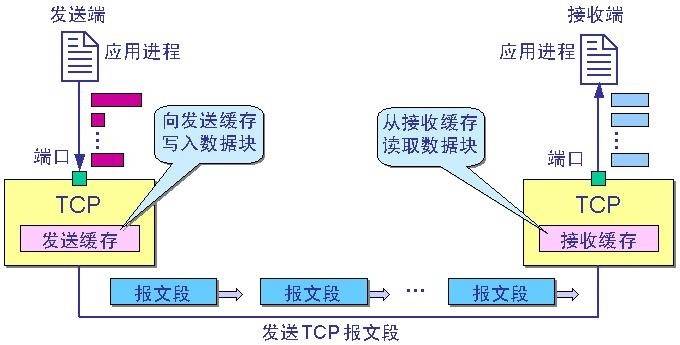
发送端的字节流都会先传入缓冲区,再通过网络传入到接收端的缓冲区中,最终由接收端获取。
2、TCP粘包和拆包概念
因为TCP会根据缓冲区的实际情况进行包的划分,在业务上认为,有的包被拆分成多个包进行发送,也可能多个晓小的包封装成一个大的包发送,这就是TCP的粘包或者拆包。
3、TCP粘包和拆包图解
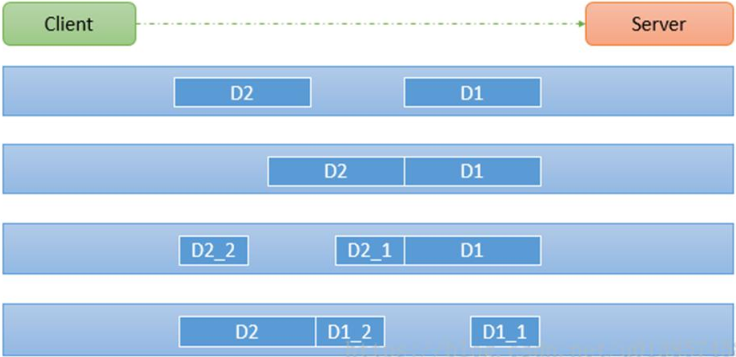
假设客户端分别发送了两个数据包D1和D2给服务端,由于服务端一次读取到字节数是不确定的,故可能存在以下几种情况:
- 服务端分两次读取到两个独立的数据包,分别是D1和D2,没有粘包和拆包。
- 服务端一次接收到了两个数据包,D1和D2粘在一起,发生粘包。
- 服务端分两次读取到数据包,第一次读取到了完整的D1包和D2包的部分内容,第二次读取到了D2包的剩余内容,发生拆包。
- 服务端分两次读取到数据包,第一次读取到部分D1包,第二次读取到剩余的D1包和全部的D2包。
当TCP缓存再小一点的话,会把D1和D2分别拆成多个包发送。
4、TCP粘包和拆包解决策略
因为TCP只负责数据发送,并不处理业务上的数据,所以只能在上层应用协议栈解决,目前的解决方案归纳:
- 消息定长,每个报文的大小固定,如果数据不够,空位补空格。
- 在包的尾部加回车换行符标识。
- 将消息分为消息头与消息体,消息头中包含消息总长度。
- 设计更复杂的协议。
5、Netty中的解决办法
Netty提供了多种默认的编码器解决粘包和拆包: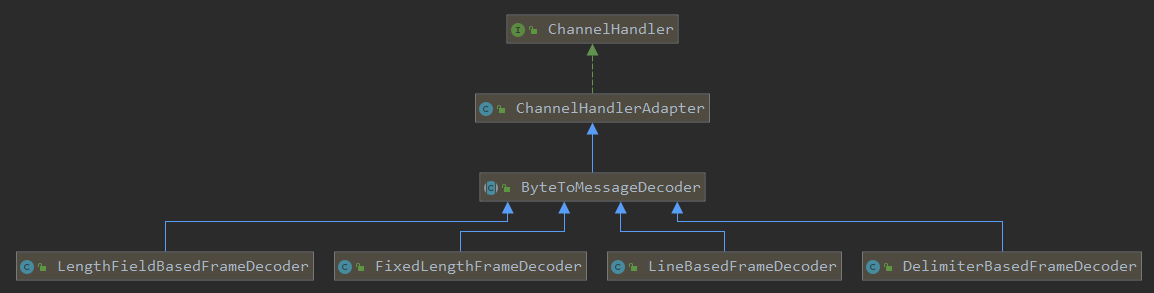
5.1、LineBasedFrameDecoder
基于回车换行符的解码器,当遇到”\n”或者 “\r\n”结束符时,分为一组。支持携带结束符或者不带结束符两种编码方式,也支持配置单行的最大长度。
LineBasedFrameDecoder与StringDecoder搭配时,相当于按行切换的文本解析器,用来支持TCP的粘包和拆包。
使用例子:
1 | private void start() throws Exception { |
注意ChannelPipeline 中ChannelHandler的顺序,
5.2、DelimiterBasedFrameDecoder
分隔符解码器,可以指定消息结束的分隔符,它可以自动完成以分隔符作为码流结束标识的消息的解码。回车换行解码器实际上是一种特殊的DelimiterBasedFrameDecoder解码器。
使用例子(后面的代码只贴ChannelPipeline部分):
1 | ChannelPipeline p = ch.pipeline(); |
5.3、FixedLengthFrameDecoder
固定长度解码器,它能够按照指定的长度对消息进行自动解码,当制定的长度过大,消息过短时会有资源浪费,但是使用起来简单。
1 | ChannelPipeline p = ch.pipeline(); |
5.4、LengthFieldBasedFrameDecoder
通用解码器,一般协议头中带有长度字段,通过使用LengthFieldBasedFrameDecoder传入特定的参数,来解决拆包粘包。
io.netty.handler.codec.LengthFieldBasedFrameDecoder的实例化:
1 | /** |
- maxFrameLength
最大帧长度。也就是可以接收的数据的最大长度。如果超过,此次数据会被丢弃。 - lengthFieldOffset
长度域偏移。就是说数据开始的几个字节可能不是表示数据长度,需要后移几个字节才是长度域。 - lengthFieldLength
长度域字节数。用几个字节来表示数据长度。 - lengthAdjustment
数据长度修正。因为长度域指定的长度可以是header+body的整个长度,也可以只是body的长度。如果表示header+body的整个长度,那么我们需要修正数据长度。 - initialBytesToStrip
跳过的字节数。如果你需要接收header+body的所有数据,此值就是0,如果你只想接收body数据,那么需要跳过header所占用的字节数。 - failFast
如果为true,则在解码器注意到帧的长度将超过maxFrameLength时立即抛出TooLongFrameException,而不管是否已读取整个帧。
如果为false,则在读取了超过maxFrameLength的整个帧之后引发TooLongFrameException。
下面通过Netty源码中LengthFieldBasedFrameDecoder的注释几个例子看一下参数的使用:
5.4.1、2 bytes length field at offset 0, do not strip header
本例中的length字段的值是12 (0x0C),它表示“HELLO, WORLD”的长度。默认情况下,解码器假定长度字段表示长度字段后面的字节数。
- lengthFieldOffset = 0: 开始的2个字节就是长度域,所以不需要长度域偏移。
- lengthFieldLength = 2: 长度域2个字节。
- lengthAdjustment = 0: 数据长度修正为0,因为长度域只包含数据的长度,所以不需要修正。
- initialBytesToStrip = 0: 发送和接收的数据完全一致,所以不需要跳过任何字节。

5.4.2、2 bytes length field at offset 0, strip header
因为我们可以通过调用readableBytes()来获得内容的长度,所以可能希望通过指定initialbystrip来删除长度字段。在本例中,我们指定2(与length字段的长度相同)来去掉前两个字节。
- lengthFieldOffset = 0: 开始的2个字节就是长度域,所以不需要长度域偏移。
- lengthFieldLength = 2 :长度域2个字节。
- lengthAdjustment = 0: 数据长度修正为0,因为长度域只包含数据的长度,所以不需要修正。
- initialBytesToStrip = 2 :我们发现接收的数据没有长度域的数据,所以要跳过长度域的2个字节。
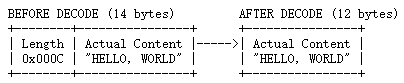
5.4.3、2 bytes length field at offset 0, do not strip header, the length field represents the length of the whole message
在大多数情况下,length字段仅表示消息体的长度,如前面的示例所示。但是,在一些协议中,长度字段表示整个消息的长度,包括消息头。在这种情况下,我们指定一个非零长度调整。因为这个示例消息中的长度值总是比主体长度大2,所以我们指定-2作为补偿的长度调整。
- lengthFieldOffset = 0: 开始的2个字节就是长度域,所以不需要长度域偏移。
- lengthFieldLength = 2: 长度域2个字节。
- lengthAdjustment = -2 :因为长度域为总长度,所以我们需要修正数据长度,也就是减去2。
- initialBytesToStrip = 0 :发送和接收的数据完全一致,所以不需要跳过任何字节。

5.4.4、3 bytes length field at the end of 5 bytes header, do not strip header
下面的消息是第一个示例的简单变体。一个额外的头值被预先写入消息中。长度调整再次为零,因为译码器在计算帧长时总是考虑到预写数据的长度。
- lengthFieldOffset = 2 :(= the length of Header 1)跳过2字节之后才是长度域
- lengthFieldLength = 3:长度域3个字节。
- lengthAdjustment = 0:数据长度修正为0,因为长度域只包含数据的长度,所以不需要修正。
- initialBytesToStrip = 0:发送和接收的数据完全一致,所以不需要跳过任何字节。

5.4.5、3 bytes length field at the beginning of 5 bytes header, do not strip header
这是一个高级示例,展示了在长度字段和消息正文之间有一个额外头的情况。您必须指定一个正的长度调整,以便解码器将额外的标头计数到帧长度计算中。
- lengthFieldOffset = 0:开始的就是长度域,所以不需要长度域偏移。
- lengthFieldLength = 3:长度域3个字节。
- lengthAdjustment = 2 :(= the length of Header 1) 长度修正2个字节,加2
- initialBytesToStrip = 0:发送和接收的数据完全一致,所以不需要跳过任何字节。

5.4.6、2 bytes length field at offset 1 in the middle of 4 bytes header, strip the first header field and the length field
这是上述所有示例的组合。在长度字段之前有预写的header,在长度字段之后有额外的header。预先设置的header会影响lengthFieldOffset,而额外的leader会影响lengthAdjustment。我们还指定了一个非零initialBytesToStrip来从帧中去除长度字段和预定的header。如果不想去掉预写的header,可以为initialBytesToSkip指定0。
- lengthFieldOffset = 1 :(= the length of HDR1) ,跳过1个字节之后才是长度域
- lengthFieldLength = 2:长度域2个字节
- lengthAdjustment = 1: (= the length of HDR2)
- initialBytesToStrip = 3 :(= the length of HDR1 + LEN)

5.4.7、2 bytes length field at offset 1 in the middle of 4 bytes header, strip the first header field and the length field, the length field represents the length of the whole message
让我们对前面的示例进行另一个修改。与前一个示例的惟一区别是,length字段表示整个消息的长度,而不是消息正文的长度,就像第三个示例一样。我们必须把HDR1的长度和长度计算进长度调整里。请注意,我们不需要考虑HDR2的长度,因为length字段已经包含了整个头的长度。
- lengthFieldOffset = 1:长度域偏移1个字节,之后才是长度域。
- lengthFieldLength = 2:长度域2个字节。
- lengthAdjustment = -3: (= the length of HDR1 + LEN, negative)数据长度修正-3个字节。
- initialBytesToStrip = 3:因为接受的数据比发送的数据少3个字节,所以跳过3个字节。