对接ElasticSearch注意事项
1、分词
尽量不用Ngram,但是如果要查询更准确,还是需要用Ngram,但是需要控制每个需要分词的长度大小,比如手机号11位,车牌号8位等限制。
2、索引实时性要求是啥?
是有几秒的延迟,能接受几秒。
3、最多支持查看多少页以后的数据?
会对系统有较大压力,例如每页100,查第10000页,那就要处理100万的数据,这个是一个搜索系统,不是导出,所以也不是很有必要跳转到很大的页数。
4、客户姓名要求拼音模糊搜吗?
5、查询数量时注意
- url后要加track_total_hits=true不然超过1万,数量只给10000
- 只要count的话,可以限制size=0不反回结果https://blog.csdn.net/weixin_41804049/article/details/107177508
- rest_total_hits_as_int=true
https://blog.csdn.net/daofengsuoxiang/article/details/104776085
6、kafka申请使用
test环境只需满足命名规范,推送消息后,topic自动创建。
7、注意mapping设计时,格式问题
- mapping设计时,枚举类型的数据比较适合用keywork,带有范围查询的数据才适合用byte等格式。

- 对于时间类型,如果搜索过滤的是yyyy-MM-dd,那尽量用这种格式的字符串存储,端侧使用Date类型的属性上可加上注解@JSONField(format = “yyyy-MM-dd”)
8、全量推搜索一定要用creationtime过滤推
如果用modifiedtime和pkId过滤,会丢数据。
每天的增量数据需要用modifiedtime推送。
9、模糊查询条件分词器
测试搜索的时候,发现“es库里有个车牌号是[鄂A1234],模糊查询,如果只有“鄂A”能查到,但是“鄂A1”就查不到”。是分词效果的问题:模糊查询使用了“ik_smart”分词器。
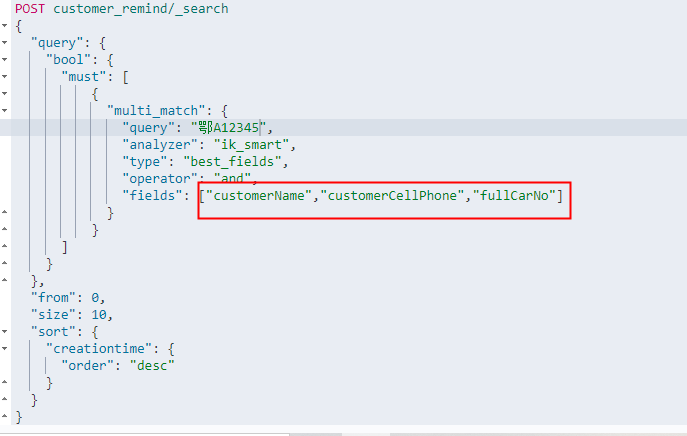
参考:Elasticsearch中ik_max_word和 ik_smart的区别
1 | GET /_analyze |
10、读搜索和推搜索需要使用客户端cluster3

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 ClawHub的技术分享!